book-riscv 操作系统接口 操作系统管理和抽象硬件,使得程序共享硬件、共享数据
内核使用cpu提供的硬件保护机制实现保护模式
文件描述符接口将文件、管道和设备之间的差异抽象出来,使它们看起来都像字节流。我们将输入和输出称为 I/O
fork和exec分开使得可以对子进程IO重定向
如果两个文件描述符是通过一系列fork和dup调用从同一个原始文件描述符派生出来的,那么它们共享一个偏移量;
父子进程各自的文件描述符表条目指向同一个文件表项
2>&1使得错误输出重定向到文件名描述符1,如果不加&表示文件1
操作系统架构 操作系统要满足复用,隔离和交互
为实现隔离,将资源抽象为服务;Unix在进程之间透明地切换硬件处理器,根据需要保存和恢复寄存器状态;文件描述符简化了交互,内核为流水线失败进程生成eof
RISC-V三种指令模式:机器模式(Machine Mode)、用户模式(User Mode)和管理模式(Supervisor Mode)
RISC-V提供ecall指定内核控制转换到管理模式的入口的,sret返回用户空间
抽象进程包括用户/管理模式标志,地址空间,线程时间切片
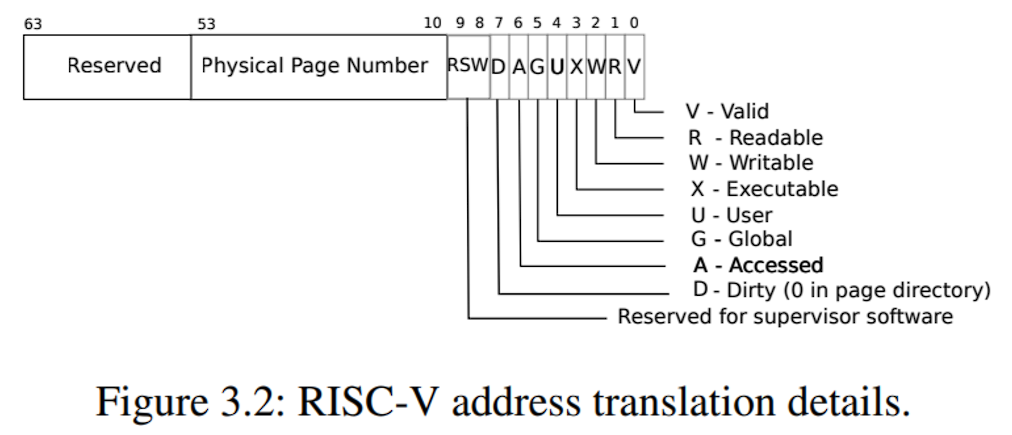
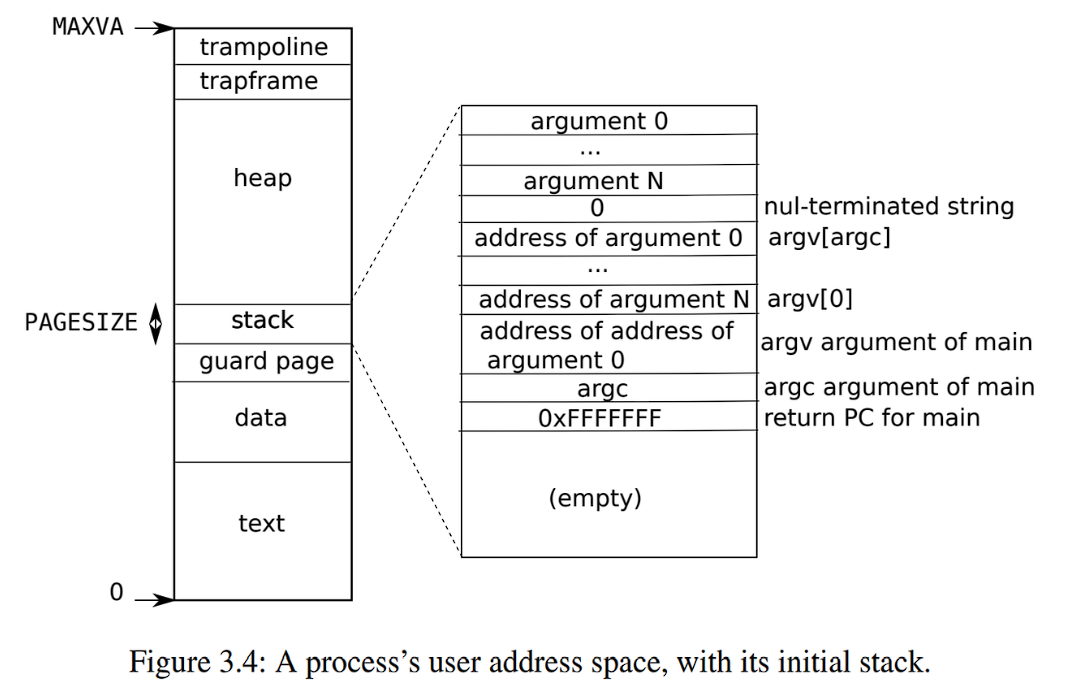
RISC-V上的指针有64位宽;硬件在页表中查找虚拟地址时只使用低39位;xv6只使用这39位中的38位,因此MAXVA=0x3fffffffff,在地址空间的顶部,xv6为trampoline(用于在用户和内核之间切换)和映射进程切换到内核的trapframe分别保留了一个页面
线程的大部分状态存储在线程栈区,进程包含用户栈和内核栈,即使用户栈被破坏,内核栈依然可以正常运行
加载程序将xv6内核加载到内存0x8000000,下面地址存放IO设备,cpu从_entry开始运行,_entry指令设置栈区,将stack0+4096加载到sp寄存器,运行start.c
start将mstatus改为管理模式,将main函数地址写入寄存器mepc,返回地址改为main,向页表寄存器satp写入0
4.3、4.4系统调用
a0,a1存放参数,a7存放系统调用号,ecall指令trap内核,执行uservec、usertrap、syscall,syscall存储系统调用号p->trapframe->a7,索引到syscalls数组,获得函数指针指向sys_exec接口,将返回值记录a0
fetchstr、copyinstr、walkaddr实现安全将数据传输到用户地址和获取用户地址的数据,walk检查虚拟地址是否用户地址,copyout将数据从内核复制到用户地址
页表 映射相同的内存到不同的地址空间中(a trampoline page),并用一个未映射的页面保护内核和用户栈区
XV6基于Sv39 RISC-V运行,只使用64位虚拟地址低39位,一个页4k,因此有2^27个PTE,每个PTE前44位为PPN,后10位为flags,生成56位物理地址
在分级页表中,根页表地址存放在satp寄存器,每个cpu都拥有
页表分级结构大大节省内存,因为不用为中间页面目录分配页面
为了减少从物理内存加载 PTE 的开销,RISC-V CPU 将页表条目缓存在 Translation Look-aside Buffer (TLB) 中
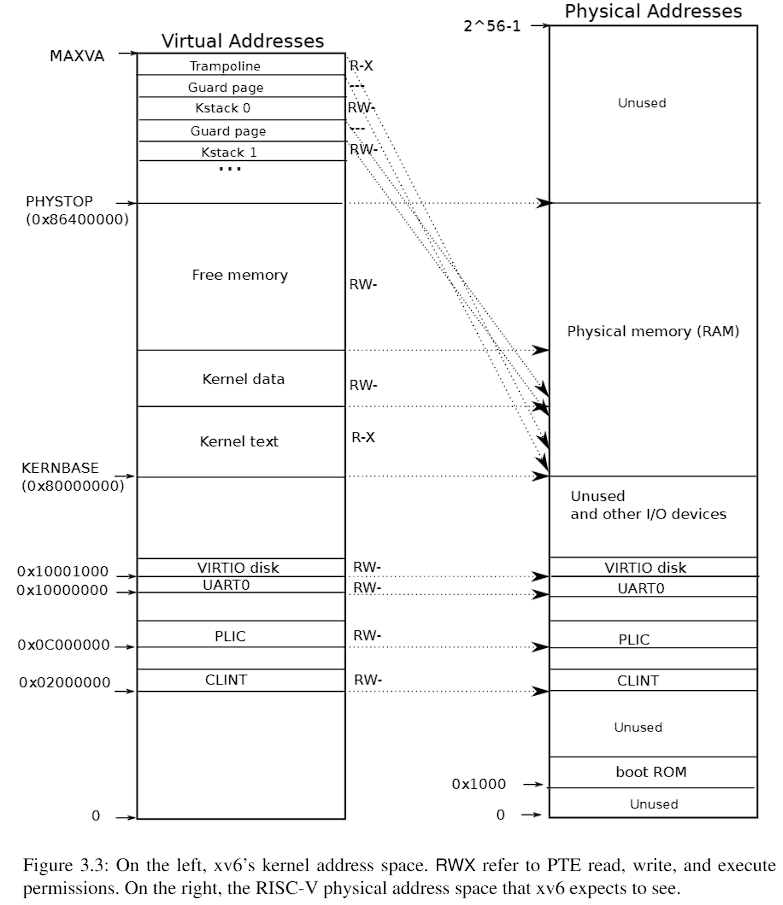
内核地址空间分配
xv6维护一个页表单独描述内核空间,为每个进程维护一个页表描述用户空间,
内核中虚拟地址和物理地址直接映射
trampoline page:映射了两次到虚拟地址
Kstack page:留下一个guard page防止栈溢出
kvminit首先分配一个pagetable_t内核页表,接着调用kvmmap直接映射图片显示那些地址,此时还未分页通过kvmmap(uint64 va, uint64 pa, uint64 sz, int perm)看到是直接映射的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void kvminit () { kernel_pagetable = (pagetable_t ) kalloc(); memset (kernel_pagetable, 0 , PGSIZE); kvmmap(UART0, UART0, PGSIZE, PTE_R | PTE_W); kvmmap(VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W); kvmmap(CLINT, CLINT, 0x10000 , PTE_R | PTE_W); kvmmap(PLIC, PLIC, 0x400000 , PTE_R | PTE_W); kvmmap(KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X); kvmmap((uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W); kvmmap(TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X); }
kvmmap就只是调用mappages设置每一个页表项
关键函数walk每次从虚拟地址获取9位来查找PTE,若PTE无效,如果设置alloc,walk将分配新页,返回最低一级PTE地址
这些代码依赖于直接映射的物理内存,也就是每次PTE可以提取下一级页表物理地址,无需转换
1 2 3 4 5 6 7 8 9 10 11 12 for (int level = 2 ; level > 0 ; level--) {pte_t *pte = &pagetable[PX(level, va)];if (*pte & PTE_V) { pagetable = (pagetable_t )PTE2PA(*pte); } else { if (!alloc || (pagetable = (pde_t *)kalloc()) == 0 ) return 0 ; memset (pagetable, 0 , PGSIZE); *pte = PA2PTE(pagetable) | PTE_V; } } return &pagetable[PX(0 , va)];
接着main调用kvminithart将内核页表写入satp 寄存器,每个RISC-V CPU将页表条目缓存在TLB ,sfence.vma刷新当前CPU的TLB
1 2 w_satp(MAKE_SATP(kernel_pagetable)); sfence_vma();
procinit为进程分配内核栈
物理内存分配
内核必须在运行时为页表、用户内存、内核栈和管道缓冲区分配和释放物理内存。xv6使用内核末尾到PHYSTOP之间的物理内存进行运行时分配。它一次分配和释放整个4096字节的页面。它使用链表的数据结构将空闲页面记录下来。分配时需要从链表中删除页面;释放时需要将释放的页面添加到链表中。
kinit初始化空闲列表以保存从内核结束到PHYSTOP之间的每一页
freerange调用kfree将每一页加入freelist链表,kfree将page每个字节填充1,即垃圾信息更快崩溃
进程地址空间
调用kalloc分配物理页面,将PTE 添加到进程的页表中,指向新的物理页面
exec
ELF文件格式:在计算机科学中,是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储格式文件。ELF是UNIX系统实验室(USL)作为应用程序二进制接口(Application Binary Interface,ABI)而开发和发布的,也是Linux的主要可执行文件格式。ELF文件由4部分组成,分别是ELF头(ELF header)、程序头表(Program header table)、节(Section)和节头表(Section header table)。实际上,一个文件中不一定包含全部内容,而且它们的位置也未必如同所示这样安排,只有ELF头的位置是固定的,其余各部分的位置、大小等信息由ELF头中的各项值来决定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 struct elfhdr { uint magic; uchar elf[12 ]; ushort type; ushort machine; uint version; uint64 entry; uint64 phoff; uint64 shoff; uint flags; ushort ehsize; ushort phentsize; ushort phnum; ushort shentsize; ushort shnum; ushort shstrndx; }; struct proghdr { uint32 type; uint32 flags; uint64 off; uint64 vaddr; uint64 paddr; uint64 filesz; uint64 memsz; uint64 align; };
exec调用proc_pagetable函数分配一个新页表,初始化用户栈,在用户栈下面放一个guard page 防止溢出;新映像若无效,跳到bad 标签,释放旧映像前等待系统调用得到返回值;ELF 文件地址可能故意引用内核,因此必须检查地址
trap and syscall 三种情况导致trap:
系统调用,ecall
异常
设备中断
处理trap四个阶段:
RISC-V CPU采取的硬件操作、为内核C代码执行而准备的汇编程序集“向量”、决定如何处理陷阱的C陷阱处理程序以及系统调用或设备驱动程序服务例程
内核通过写入寄存器来告诉CPU如何处理trap
stvec:内核在这里写入其陷阱处理程序的地址;RISC-V跳转到这里处理陷阱。sepc:当发生陷阱时,RISC-V会在这里保存程序计数器pc(因为pc会被stvec覆盖)。sret(从陷阱返回)指令会将sepc复制到pc。内核可以写入sepc来控制sret的去向。scause: RISC-V在这里放置一个描述陷阱原因的数字。sscratch:保存指向trapframe地址,一开始就会用到sstatus:其中的SIE 位控制设备中断是否启用。如果内核清空SIE ,RISC-V将推迟设备中断,直到内核重新设置SIE 。SPP 位指示陷阱是来自用户模式还是管理模式,并控制sret返回的模式。fp:指向栈顶
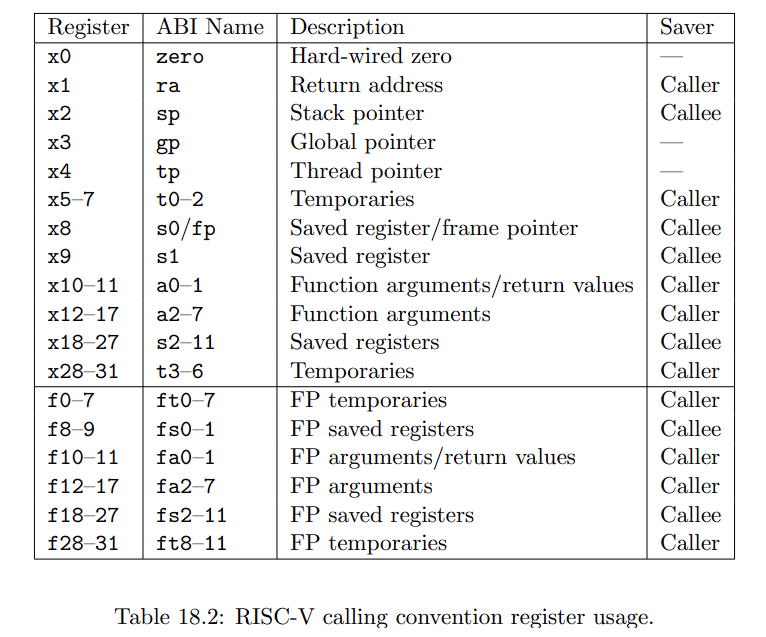
在RV32和RV64中long和指针都与整数寄存器一样宽,32和64
七个整数寄存器t0-t6和十二个浮点寄存器ft0-ft11是临时寄存器,它们在调用之间是易失的,如果稍后使用,必须由调用者保存。十二个整数寄存器s0-s11和十二个浮点寄存器fs0-fs11在调用之间被保留,如果使用,必须由被调用者保存。
当需要强制执行陷阱时,RISC-V硬件对所有陷阱类型(计时器中断除外)执行以下操作:
如果陷阱是设备中断,并且状态SIE 位被清空,则不执行以下任何操作。
清除SIE 以禁用中断。
将pc复制到sepc。
将当前模式(用户或管理)保存在状态的SPP 位中。
设置scause以反映产生陷阱的原因。
将模式设置为管理模式。
将stvec复制到pc。
在新的pc上开始执行。
使用专门的stvev寄存器获内核指定的指令地址是必要的,因为CPU不会切换内核页表,不会切换内核栈,不会保存除pc之外寄存器,因此当切换到管理模式而没有切换PC,内核则会访问到用户指令,例如用户程序修改satp寄存器使其指向一个允许访问所有物理内存的页表
陷入trap机制: 当用户产生trap,跳转到stvec指定地址执行uservec,然后usertrap;返回时先usertrapret,然后userret
一个巧妙的设计 是使用trampoline page保存uservec,这样在用户空间的内核空间就有相同的映射,当切换内核表时内核也可以正常工作
在trampoline.S中,.section trampsec指定代码在trampsec的section中,uservec汇编代码首先csrrw切换a0和sscratch寄存器的值,这样a0指向了trapframe,通过a0+偏移量就可以保存32个寄存器的值了,最后设置sp、tp、t0、t1寄存器就跳转到usertrap
在usertrap:确定trap原因是上面三种情况的哪一种,,更改stvec指向kernelvec,将sepc写入p->trapframe->epc,因为当陷阱由定时器中断触发的话,yield 切换到另一个进程的内核线程,而该进程可能返回到用户空间,在该过程中它将修改sepc
RISC-V使用scause寄存器来指示触发缺页异常的原因,而stval寄存器则包含了无法被转换的地址。
usertrapret:调用userret切换用户页表,a0和a1指向TRAPFRAME和用户页表
userret:恢复保存的寄存器值,csrrw,sret返回用户空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 # # code to switch between user and kernel space. # # this code is mapped at the same virtual address # (TRAMPOLINE) in user and kernel space so that # it continues to work when it switches page tables. # # kernel.ld causes this to be aligned # to a page boundary. # .section trampsec .globl trampoline trampoline: .align 4 .globl uservec uservec: # # trap.c sets stvec to point here, so # traps from user space start here, # in supervisor mode, but with a # user page table. # # sscratch points to where the process's p->trapframe is # mapped into user space, at TRAPFRAME. # # swap a0 and sscratch # so that a0 is TRAPFRAME csrrw a0, sscratch, a0 # save the user registers in TRAPFRAME sd ra, 40(a0) sd sp, 48(a0) sd gp, 56(a0) sd tp, 64(a0) sd t0, 72(a0) sd t1, 80(a0) sd t2, 88(a0) sd s0, 96(a0) sd s1, 104(a0) sd a1, 120(a0) sd a2, 128(a0) sd a3, 136(a0) sd a4, 144(a0) sd a5, 152(a0) sd a6, 160(a0) sd a7, 168(a0) sd s2, 176(a0) sd s3, 184(a0) sd s4, 192(a0) sd s5, 200(a0) sd s6, 208(a0) sd s7, 216(a0) sd s8, 224(a0) sd s9, 232(a0) sd s10, 240(a0) sd s11, 248(a0) sd t3, 256(a0) sd t4, 264(a0) sd t5, 272(a0) sd t6, 280(a0) # save the user a0 in p->trapframe->a0 csrr t0, sscratch sd t0, 112(a0) # restore kernel stack pointer from p->trapframe->kernel_sp ld sp, 8(a0) # make tp hold the current hartid, from p->trapframe->kernel_hartid ld tp, 32(a0) # load the address of usertrap(), p->trapframe->kernel_trap ld t0, 16(a0) # restore kernel page table from p->trapframe->kernel_satp ld t1, 0(a0) csrw satp, t1 sfence.vma zero, zero # a0 is no longer valid, since the kernel page # table does not specially map p->tf. # jump to usertrap(), which does not return jr t0 .globl userret userret: # userret(TRAPFRAME, pagetable) # switch from kernel to user. # usertrapret() calls here. # a0: TRAPFRAME, in user page table. # a1: user page table, for satp. # switch to the user page table. csrw satp, a1 sfence.vma zero, zero # put the saved user a0 in sscratch, so we # can swap it with our a0 (TRAPFRAME) in the last step. ld t0, 112(a0) csrw sscratch, t0 # restore all but a0 from TRAPFRAME ld ra, 40(a0) ld sp, 48(a0) ld gp, 56(a0) ld tp, 64(a0) ld t0, 72(a0) ld t1, 80(a0) ld t2, 88(a0) ld s0, 96(a0) ld s1, 104(a0) ld a1, 120(a0) ld a2, 128(a0) ld a3, 136(a0) ld a4, 144(a0) ld a5, 152(a0) ld a6, 160(a0) ld a7, 168(a0) ld s2, 176(a0) ld s3, 184(a0) ld s4, 192(a0) ld s5, 200(a0) ld s6, 208(a0) ld s7, 216(a0) ld s8, 224(a0) ld s9, 232(a0) ld s10, 240(a0) ld s11, 248(a0) ld t3, 256(a0) ld t4, 264(a0) ld t5, 272(a0) ld t6, 280(a0) # restore user a0, and save TRAPFRAME in sscratch csrrw a0, sscratch, a0 # return to user mode and user pc. # usertrapret() set up sstatus and sepc. sret
Page-fault RISC-V架构区分了三种类型的缺页异常:
加载缺页(load page faults):当加载指令无法将其虚拟地址转换为物理地址时触发。
存储缺页(store page faults):当存储指令无法将其虚拟地址转换为物理地址时触发。
指令缺页(instruction page faults):当程序计数器中的地址无法转换为物理地址时触发。
COW好处:
在fork中简单的uvmcopy分配物理内存和复制页表,真实实现了COW fork,最初共享只读(~PTE_W),当写入时引发页面异常错误,然后内核复制了包含错误地址的页面。
这里同时在父子进程只拷贝缺少的页面,因此fork后立即exec,只会拷贝少量页面,高效
lazy allocation:sbrk时内核记录大小增加,写时分配
磁盘分页:内核只需为一个庞大的程序分配需要用到的物理内存,将PTEs标记无效,根据内存表现实现分页到磁盘
自动扩展栈空间和内存映射文件
中断和设备驱动 许多设备驱动程序在两种环境中执行代码:上半部分在进程的内核线程中运行,下半部分在中断时执行。上半部分通过系统调用 进行调用,动程序的中断处理程序 充当下半部分
控制台输入:
Xv6的main函数调用consoleinit来初始化UART硬件。该代码配置UART:UART对接收到的每个字节的输入生成一个接收中断,对发送完的每个字节的输出生成一个发送完成中断
shell通过init.c打开的文件描述符读取输入,对read的调用最终到达consoleread ,可以看到consoleread的sleep导致read阻塞
用户输入字符后UART硬件要求RISC-V发出一个中断,调用devintr,根据scause寄存器的值判断外设。通过PLIC获取设备中断,例如UART调用uartintr。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int devintr () uint64 scause = r_scause (); if ((scause & 0x8000000000000000L ) && (scause & 0xff ) == 9 ){ int irq = plic_claim (); if (irq == UART0_IRQ){ uartintr (); } else if (irq == VIRTIO0_IRQ){ virtio_disk_intr (); } ... }
uartintr从UART硬件读取所有等待输入的字符,并将它们交给consoleintr
1 2 3 4 5 6 while (1 ){int c = uartgetc ();if (c == -1 ) break ; consoleintr (c);}
consoleintr的工作是在cons.buf 中积累输入字符,直到一整行到达然后唤醒consoleread,C(‘D’)表示文件结束或者缓冲区满,更新e,并且更新w这样consoleread知道新的输入可用,唤醒所有因cons.r而睡眠的进程
1 2 3 4 5 6 7 cons.buf[cons.e++ % INPUT_BUF] = c; if (c == '\n' || c == C ('D' ) || cons.e == cons.r+INPUT_BUF){cons.w = cons.e; wakeup (&cons.r);}
consoleread从sleep醒来后将cons.buf缓存区每个字符发送到用户空间,直接一整行或者又进入sleep
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 int consoleread (int user_dst, uint64 dst, int n) uint target; int c; char cbuf; target = n; acquire (&cons.lock); while (n > 0 ){ while (cons.r == cons.w){ if (myproc ()->killed){ release (&cons.lock); return -1 ; } sleep (&cons.r, &cons.lock); } c = cons.buf[cons.r++ % INPUT_BUF]; if (c == C ('D' )){ if (n < target){ cons.r--; } break ; } cbuf = c; if (either_copyout (user_dst, dst, &cbuf, 1 ) == -1 ) break ; dst++; --n; if (c == '\n' ){ break ; } } release (&cons.lock); return target - n; }
控制台输出 :
write最终到达uartputc,uartputc将字符添加到缓存区uart_tx_buf ,满时等待,调用uartstart启动设备传输并写入THR 寄存器一个字节,UART 传输该字节生成中断调用uartintr,其余的字节会在uartintr触发的传输完成中断到达时,由uartstart调用发送。
锁
锁 描述
bcache.lock保护块缓冲区缓存项(block buffer cache entries)的分配
cons.lock串行化对控制台硬件的访问,避免混合输出
ftable.lock串行化文件表中文件结构体的分配
icache.lock保护索引结点缓存项(inode cache entries)的分配
vdisk_lock串行化对磁盘硬件和DMA描述符队列的访问
kmem.lock串行化内存分配
log.lock串行化事务日志操作
管道的pi->lock
串行化每个管道的操作
pid_lock串行化next_pid的增量
进程的p->lock
串行化进程状态的改变
tickslock串行化时钟计数操作
索引结点的 ip->lock
串行化索引结点及其内容的操作
缓冲区的b->lock
串行化每个块缓冲区的操作
竞态条件 是指多个进程读写某些共享数据(至少有一个访问是写入)的情况。尽管正确使用锁可以改正不正确的代码,但锁使得CPU串行化限制了性能
自旋锁:
在RISC-V上,原子指令是amoswap r, a。amoswap读取内存地址a处的值,将寄存器r的内容写入该地址,并将其读取的值放入r中。
acquire使用执行原子赋值的C库函数__sync_lock_test_and_set;release使用执行原子赋值的C库函数__sync_lock_release
睡眠锁
睡眠锁有一个被自旋锁保护的锁定字段,acquiresleep对sleep的调用原子地让出CPU并释放自旋锁
当CPU获取任何锁时,xv6总是禁用该CPU上的中断。
acquire调用push_off 并且release调用pop_off来跟踪当前CPU上锁的嵌套级别。当计数达到零时,pop_off恢复最外层临界区域开始时存在的中断使能状态。intr_off和intr_on函数执行RISC-V指令分别用来禁用和启用中断。
编译器和CPU在重新排序时需要遵循一定规则,以确保它们不会改变正确编写的串行代码的结果。然而,规则确实允许重新排序后改变并发代码的结果,并且很容易导致多处理器上的不正确行为。CPU的排序规则称为内存模型 (memory model)。xv6在acquire和release中都使用了__sync_synchronize()。__sync_synchronize()是一个内存障碍:它告诉编译器和CPU不要跨障碍重新排序load或store指令
调度 多路复用:
当进程等待设备或管道I/O完成,或等待子进程退出,或在sleep系统调用中等待时,xv6使用睡眠(sleep)和唤醒(wakeup)机制切换。
xv6周期性地强制切换以处理长时间计算而不睡眠的进程。
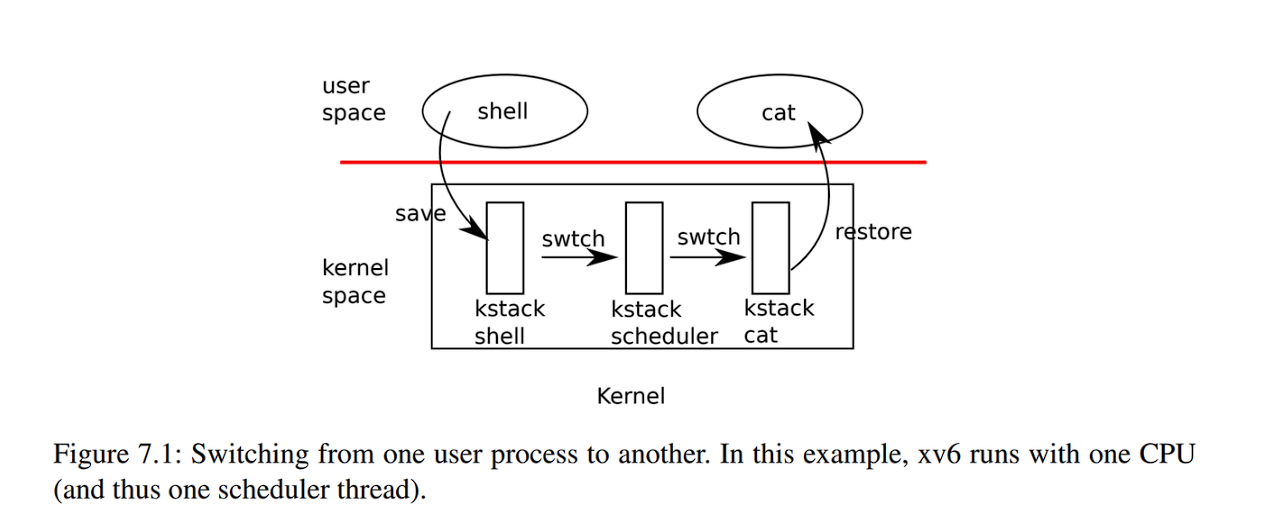
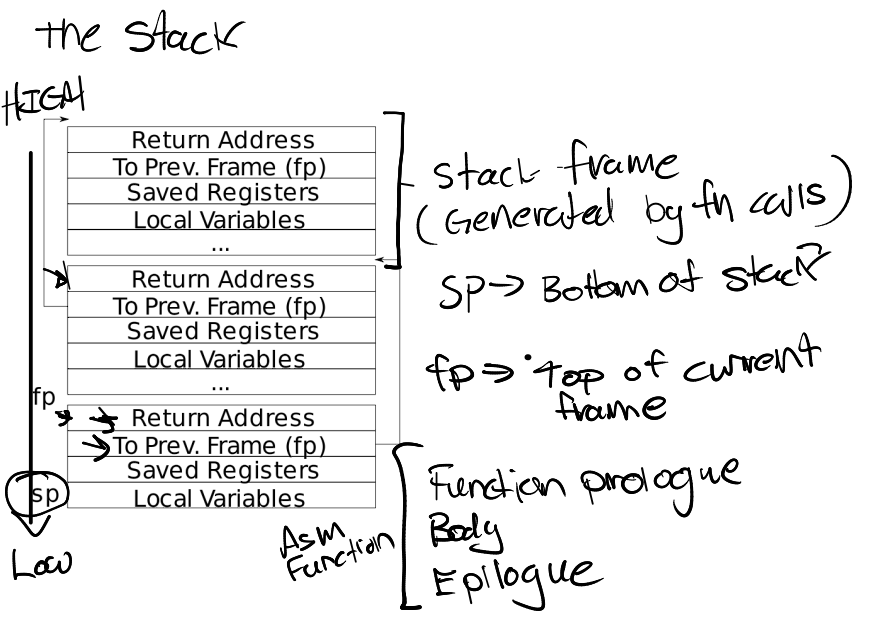
上下文切换 调用swtch来保存自己的上下文并返回到调度程序的上下文。接受两个参数:struct context *old和struct context *new。
中断结束时的一种可能性是usertrap调用了yield。依次地:Yield调用sched,sched调用swtch将当前上下文保存在p->context中,并切换到先前保存在cpu->scheduler中的调度程序上下文。swtch.S中只保存s0-s11,即callee-saved register
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 void yield (void ) struct proc *p = myproc (); acquire (&p->lock); p->state = RUNNABLE; sched (); release (&p->lock); } void sched (void ) int intena; struct proc *p = myproc (); if (!holding (&p->lock)) panic ("sched p->lock" ); if (mycpu ()->noff != 1 ) panic ("sched locks" ); if (p->state == RUNNING) panic ("sched running" ); if (intr_get ()) panic ("sched interruptible" ); intena = mycpu ()->intena; swtch (&p->context, &mycpu ()->context); mycpu ()->intena = intena; } void scheduler (void ) struct proc *p; struct cpu *c = mycpu (); c->proc = 0 ; for (;;){ intr_on (); int nproc = 0 ; for (p = proc; p < &proc[NPROC]; p++) { acquire (&p->lock); if (p->state != UNUSED) { nproc++; } if (p->state == RUNNABLE) { p->state = RUNNING; c->proc = p; swtch (&c->context, &p->context); c->proc = 0 ; } release (&p->lock); } if (nproc <= 2 ) { intr_on (); asm volatile ("wfi" ) } } }
[!NOTE]
在RISCV架构中,caller-saved寄存器在进去函数前由调用方被保存,在调用函数中,callee-saved寄存器如果需要修改则由被调用方修改和函数返回时恢复;swtch 汇编保存s0-s11是callee-saved寄存器,caller-saved寄存器在调用swtch前被保存在栈上了,这里进程上下文切换可用简单的看似函数调用,因此需要手动保存s0-s11,ra保存swtch下条指令地址,因此不需要保存pc;Swtch在调度程序的栈上返回,就像是scheduler的swtch返回一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 .globl swtch swtch: sd ra, 0(a0) sd sp, 8(a0) sd s0, 16(a0) sd s1, 24(a0) sd s2, 32(a0) sd s3, 40(a0) sd s4, 48(a0) sd s5, 56(a0) sd s6, 64(a0) sd s7, 72(a0) sd s8, 80(a0) sd s9, 88(a0) sd s10, 96(a0) sd s11, 104(a0) ld ra, 0(a1) ld sp, 8(a1) ld s0, 16(a1) ld s1, 24(a1) ld s2, 32(a1) ld s3, 40(a1) ld s4, 48(a1) ld s5, 56(a1) ld s6, 64(a1) ld s7, 72(a1) ld s8, 80(a1) ld s9, 88(a1) ld s10, 96(a1) ld s11, 104(a1) ret
sleep和wakeup xv6睡眠和唤醒被用作条件同步机制
P持有s->lock的事实阻止V在P检查s->count和调用sleep之间试图唤醒它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void V (struct semaphore* s) acquire (&s->lock); s->count += 1 ; wakeup (s); release (&s->lock); } void P (struct semaphore* s) acquire (&s->lock); while (s->count == 0 ) sleep (s, &s->lock); s->count -= 1 ; release (&s->lock); }
sleep函数
sleep函数使得当前进程进入SLEEPING状态,并调用sched函数释放CPU控制权。sleep函数需要传入一个等待通道(chan),进程将在该通道上等待被唤醒。在调用sleep之前,进程必须持有一个互斥锁(lk),以确保在进入睡眠状态之前没有其他进程能够调用wakeup。
sleep函数会获取进程自身的锁p->lock,释放传入的锁lk,以保护进程状态的修改。进程在sleep之后,将不会被调度器再次选择执行,直到它被wakeup唤醒。
wakeup函数
wakeup函数用于唤醒所有在指定通道上睡眠的进程。它遍历进程表,对于每个在SLEEPING状态且等待指定通道的进程,将其状态更改为RUNNABLE。
wakeup在修改进程状态时需要获取进程锁p->lock,以确保状态的一致性。
文件系统 xv6文件系统实现分为七层
文件描述符(File descriptor)
文件描述符层使用文件系统接口抽象了许多Unix资源(例如,管道、设备、文件等)
路径名(Pathname)
路径名层提供了分层路径名,如***/usr/rtm/xv6/fs.c***,并通过递归查找来解析它们
目录(Directory)
目录层将每个目录实现为一种特殊的索引结点,其内容是一系列目录项,每个目录项包含一个文件名和索引号
索引结点(Inode)
每个文件表示为一个索引结点
日志(Logging)
日志记录层允许更高层在一次事务(transaction)中将更新包装到多个块,并确保在遇到崩溃时自动更新这些块
缓冲区高速缓存(Buffer cache)
缓冲区高速缓存层缓存磁盘块并同步对它们的访问
磁盘(Disk)
磁盘层读取和写入virtio硬盘上的块
// File system implementation. Five layers:
// + Blocks: allocator for raw disk blocks.
// + Log: crash recovery for multi-step updates.
// + Files: inode allocator, reading, writing, metadata.
// + Directories: inode with special contents (list of other inodes!)
// + Names: paths like /usr/rtm/xv6/fs.c for convenient naming.
Buffer cache层 bread获取一个buf ,其中包含一个可以在内存中读取或修改的块的副本;bwrite;将修改后的缓冲区写入磁盘上的相应块。
Buffer cache每个缓冲区使用一个睡眠锁,bread返回一个上锁的缓冲区,brelse释放该锁;使用LRU置换
1 2 3 4 5 struct { struct spinlock lock; struct buf buf[NBUF]; struct buf head; } bcache;
binit使用静态buf[NBUF]初始化,并通过head循环链表的形式进行访问,以此来LRU置换
1 2 3 4 5 6 7 8 9 bcache.head.prev = &bcache.head; bcache.head.next = &bcache.head; for (b = bcache.buf; b < bcache.buf+NBUF; b++){b->next = bcache.head.next; b->prev = &bcache.head; initsleeplock (&b->lock, "buffer" );bcache.head.next->prev = b; bcache.head.next = b; }
bread(uint dev, uint blockno)调用bget(uint dev, uint blockno)循环链表获取缓存区,若没有匹配,则从pre往前遍历,符合LRU,修改valid字段 为0并返回一个buf来进行磁盘读块 virtio_disk_rw(b, 0);
struct buf中的sleeplock保证了同时对同一个buf进行bread只有一个进程获得能得对buf的引用
brelse(struct buf *b)释放缓存区并移至链表最前面,一遍bget使用从后往前扫描最近最少使用
日志层 xv6会在磁盘上的log (日志)中放置它希望进行的所有磁盘写入的描述。一旦系统调用记录了它的所有写入操作,它就会向磁盘写入一条特殊的commit (提交)记录,表明日志包含一个完整的操作;写入磁盘后再擦除磁盘日志;若未提交则忽略,若已提交则重复操作,在任何一种情况下,日志都会使操作在崩溃时成为原子操作
日志驻留在超级块中指定的已知固定位置。
它由一个头块(header block)和一系列更新块的副本(logged block)组成。
n为记录块数量,为0表示没有事务,非0表示日志包含一个完整的已提交事务
在事务提交(commit)时Xv6才向头块写入数据,在将logged blocks复制到文件系统后将计数设置为零
日志系统可以将多个系统调用的写操作累积到一个事务中,这称为组提交(group commit);组提交减少了磁盘操作次数,因为它将提交的固定成本分摊到多个操作上。
组提交还可以在同一个磁盘旋转期间将多个并发写操作交给磁盘系统,可能允许磁盘在单次旋转中全部写入
写操作(write)和删除操作(unlink)可能写入许多块,因此xv6的写系统调用将大的写操作分解为适合日志空间的多个较小的写操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct logheader { int n; int block[LOGSIZE]; }; struct log { struct spinlock lock; int start; int size; int outstanding; int committing; int dev; struct logheader lh; };
典型使用文件系统调用,以下表示一个事务开始和结束
begin_op()检查log.committing和log.lh.n + (log.outstanding+1)*MAXOPBLOCKS > LOGSIZE当没有提交进行或者空间足够时,log.outstanding += 1;预定空间;否则sleep
end_op()减少系统调用次数,非0时wakeup唤醒begin_op此时有空间,为0时进行提交,commit()分为四个阶段:
write_log()写入日志;log.ln.n和log.ln.block记录系统调用的块(cache block),复制到日志槽(log block)中(即long.start+1磁盘块开始)bread(log.dev, log.start+tail+1)write_head()写入头块,即long.start磁盘块来存储头块:(struct logheader *) bread(log.dev, log.start);install_trans写入文件系统,跟write_log()相反log.lh.n = 0;计数清零,再次调用write_head()
1 2 3 4 5 6 7 begin_op(); ... bp = bread(...); bp->data[...] = ...; log_write(bp); ... end_op();
inode层 磁盘上的inode由struct dinode定义,type为零表示磁盘inode是空闲的。字段nlink统计引用此inode的目录项的数量
struct inode是磁盘dinode的内存副本,只有当有C指针引用某个inode时,内核才会在内存中存储该inode。由ref字段统计引用次数,可以来自文件描述符、当前工作目录和如exec的瞬态内核代码。
provide a place for synchronizing access to inodes used by multiple processes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct dinode { short type; short major; short minor; short nlink; uint size; uint addrs[NDIRECT+1 ]; }; struct inode { uint dev; uint inum; int ref; struct sleeplock lock ; int valid; short type; short major; short minor; short nlink; uint size; uint addrs[NDIRECT+1 ]; };
xv6中一个block size为1k,balloc通过外部循环读取每个bmap block,内部循环bmap位获取空闲块并调用log_write()将blockno即获取的空闲块号写入到日志头块中
inode缓存是直写的,这意味着修改已缓存inode的代码必须立即使用iupdate将其写入磁盘。
Ialloc类似于balloc:一次只有一个进程可以保存对bp的引用
iget返回inode的引用或者空槽
iput减少引用,当最后一个引用并且没有目录项指向这个文件必须调用itrunc释放
iput期间可能崩溃,这将导致文件将被标记为已在磁盘上分配,但没有目录项指向它。可用通过重启后扫描整个文件系统或记录在链表上进行释放,xv6没有解决,可能会面临磁盘空间不足的风险。
itrunc首先释放NDIRECT(12)个直接块,然后释放一个间接块(NINDIRECT),bfree操作上是将bmap对应位置0
bmap先获取直接块后再获取间接块,遇到0时分配块;Bmap使readi和writei很容易获取inode的数据。
这段代码很好的处理了偏移量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 int writei (struct inode *ip, int user_src, uint64 src, uint off, uint n) { uint tot, m; struct buf *bp ; if (off > ip->size || off + n < off) return -1 ; if (off + n > MAXFILE*BSIZE) return -1 ; for (tot=0 ; tot<n; tot+=m, off+=m, src+=m){ bp = bread(ip->dev, bmap(ip, off/BSIZE)); m = min(n - tot, BSIZE - off%BSIZE); if (either_copyin(bp->data + (off % BSIZE), user_src, src, m) == -1 ) { brelse(bp); break ; } log_write(bp); brelse(bp); } if (off > ip->size) ip->size = off; iupdate(ip); return tot; }
目录层 数据是一系列目录条目(dirent),
struct inode* dirlookup(struct inode *dp, char *name, uint *poff)查找目录项并设置poff偏移量
int dirlink(struct inode *dp, char *name, uint inum)写入目录项,若存在则iput并返回-1
1 2 3 4 struct dirent { ushort inum; char name[DIRSIZ]; };
路径名层 文件系统可靠性:
保持
可预测
原子性
同步元数据—>延迟有序写入(更新依赖问题)—>软更新
lab lab1 util sleep
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include "kernel/types.h" #include "user/user.h" int main (int argc, char *argv[]) if (argc != 2 ) { fprintf (2 , "sleep: argc != 2\n" ); exit (1 ); } int t = atoi (argv[1 ]); sleep (t); exit (0 ); }
pingpong
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" int main (int argc, char *argv[]) char buf[2 ]; int p1[2 ],p2[2 ]; pipe (p1); pipe (p2); int pid; if (fork() == 0 ) { close (p1[1 ]); close (p2[0 ]); if (read (p1[0 ], buf, sizeof (buf)) <=0 ) { fprintf (2 , "child failed read ping\n" ); exit (1 ); } pid = getpid (); printf ("<%d> received ping\n" , pid); if (write (p2[1 ], "o" , 1 ) < 1 ) { fprintf (2 , "child failed write pong\n" ); exit (1 ); } close (p1[0 ]); close (p2[1 ]); exit (0 ); } close (p1[0 ]); close (p2[1 ]); if (write (p1[1 ], "i" , 1 ) < 1 ) { fprintf (2 , "parent failed write ping\n" ); exit (1 ); } if (read (p2[0 ], buf, 1 ) <= 0 ) { fprintf (2 , "parent failed read pong\n" ); exit (1 ); } pid = getpid (); printf ("<%d> received pong\n" , pid); close (p1[1 ]); close (p2[0 ]); exit (0 ); }
primes
我这里只试到37就报错pipe失败了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include "kernel/types.h" #include "user/user.h" void dfs (int p[2 ]) int prime; int num; close (p[1 ]); if (read (p[0 ], &prime, 4 ) != 4 ) { close (p[0 ]); exit (0 ); } printf ("prime %d\n" , prime); int p1[2 ]; if (pipe (p1) == -1 ) { fprintf (2 ,"primes: falied pipe\n" ); exit (1 ); } if (fork() == 0 ) { dfs (p1); } close (p1[0 ]); while (read (p[0 ], &num, 4 ) != 0 ) { if (num % prime) { if (write (p1[1 ], &num, 4 ) != 4 ) { fprintf (2 , "primes: failed, write\n" ); exit (1 ); } } } close (p[0 ]); close (p1[1 ]); wait (0 ); exit (0 ); } int main (int argc, char *argv[]) int p[2 ]; if (pipe (p) == -1 ) { fprintf (2 ,"primes: falied pipe\n" ); exit (1 ); } if (fork() == 0 ) { dfs (p); } close (p[0 ]); for (int i = 2 ; i <= 35 ; i++) { if (write (p[1 ], &i, 4 ) != 4 ) { fprintf (2 , "primes: falied write\n" ); exit (1 ); } } close (p[1 ]); wait (0 ); exit (0 ); }
find
基本跟ls一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fs.h" void find (const char *path, const char *filename) char buf[512 ], *p; int fd; struct dirent de; struct stat st; if ((fd = open (path, 0 )) < 0 ) { fprintf (2 , "ls: cannot open %s\n" , path); exit (1 ); } if (fstat (fd, &st) < 0 ) { fprintf (2 , "ls: cannot stat %s\n" , path); exit (1 ); } switch (st.type) { case T_FILE: fprintf (2 , "Usage: find dir file\n" ); exit (1 ); break ; case T_DIR: if (strlen (path) + 1 + DIRSIZ + 1 > sizeof buf) { printf ("ls: path too long\n" ); break ; } strcpy (buf, path); p = buf+strlen (buf); *p++ = '/' ; while (read (fd, &de, sizeof (de)) == sizeof (de)) { if (de.inum == 0 || strcmp (de.name, "." ) ==0 || strcmp (de.name, ".." ) == 0 ) continue ; memmove (p, de.name, DIRSIZ); p[DIRSIZ] = 0 ; if (stat (buf, &st) < 0 ) { printf ("ls: cannot stat %s\n" , buf); continue ; } if (st.type == T_DIR) find (buf, filename); else if (st.type == T_FILE) if (strcmp (de.name, filename) == 0 ) printf ("%s\n" , buf); } break ; } } int main (int argc, char *argv[]) if (argc != 3 ) { fprintf (2 , "find argc not 3\n" ); exit (1 ); } const char *path = argv[1 ]; const char *filename = argv[2 ]; find (path, filename); exit (0 ); }
xargs
将标准输入转换为命令行参数
1 2 3 4 5 xargs #等同于xargs echo echo -e "a\tb\tc"|xargs -d "\t" echo # 分隔符 echo 'abc'|xargs -p touch # 打印执行命令,询问;-t xargs -n 1 find -name # 每一项执行一次find -name cat foot.txt|xargs -I file sh -c 'echo file; mkdir file' # 替换字符串
这里的xargs从标准输入读取每行执行即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/param.h" int readline (char *new_argv[MAXARG], int argc) { char buf[1024 ]; int n = 0 ; while (read(0 , buf+n, 1 )) { if (n==1023 ) exit (1 ); if (buf[n] == '\n' ) break ; n++; } buf[n] = 0 ; if (n==0 ) return 0 ; int offset = 0 ; while (offset < n) { new_argv[argc++] = buf + offset; while (buf[offset] != ' ' && offset < n) offset++; while (buf[offset] == ' ' ) buf[offset++] = 0 ; } new_argv[argc] = 0 ; return n; } int main (int argc, char *argv[]) { if (argc <= 1 ) { fprintf (2 , "xargs: command(arg...)\n" ); exit (1 ); } char *command = argv[1 ]; char *new_argv[MAXARG]; for (int i = 1 ; i < argc; ++i) { new_argv[i-1 ] = malloc (strlen (argv[i])+1 ); strcpy (new_argv[i-1 ], argv[i]); } while (readline(new_argv, argc-1 )) { if (fork() == 0 ) { exec(command, new_argv); exit (1 ); } wait(0 ); } for (int i = 1 ; i < argc; ++i) free (new_argv[i-1 ]); exit (0 ); }
lab2 syscall system call tracing 打印系统调用通过在进程struct proc添加trace_mask掩码,每次调用syscall时位运算相与syscall number来打印
添加系统调用过程:在user.h添加trace系统调用接口,并在usys.pl存根,usys.pl脚本调用entry生成汇编代码,将系统调用号存到a7,调用ecall进入内核
1 2 3 4 5 6 7 8 sub entry my $name = shift ; print ".global $name \n" ; print "${name} :\n" ; print " li a7, SYS_${name} \n" ; print " ecall\n" ; print " ret\n" ; }
这时候内核并没有sys_trace,在syscall.h添加#define SYS_trace 22系统调用号,在syscall.c中添加声明extern uint64 sys_trace(void);和数组项[SYS_trace] sys_trace,
我在sysproc.c实现sys_trace函数,所有系统调用都没有参数,通过argint从a0-a7获取参数,统一参数的传递和提取(4.3,4.4有说明)
1 2 3 4 5 6 7 8 9 uint64 sys_trace (void ) { int mask; if (argint(0 , &mask) < 0 ) return -1 ; myproc()->trace_mask = mask; return 0 ; }
最后修改syscall函数,并且在fork()将trace_mask传递子进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 void syscall (void ) { int num; struct proc *p = const char *psys[] = { "" , "fork" , "exit" , "wait" , "pipe" , "read" , "kill" , "exec" , "fstat" , "chdir" , "dup" , "getpid" , "sbrk" , "sleep" , "uptime" , "open" , "write" , "mknod" , "unlink" , "link" , "mkdir" , "close" , "trace" , }; num = p->trapframe->a7; if (num > 0 && num < NELEM(syscalls) && syscalls[num]) { p->trapframe->a0 = syscalls[num](); if ((1 << num) & p->trace_mask) printf ("%d: syscall %s -> %d\n" , p->pid, psys[num], p->trapframe->a0); } else { printf ("%d %s: unknown sys call %d\n" , p->pid, p->name, num); p->trapframe->a0 = -1 ; } }
sysinfo 依照上面步骤,依然在sysproc.c添加sysinfo系统调用,在kallo.c添加freekmem(),在proc.c添加nproc(),最后在defs.h添加函数声明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 uint64 sys_sysinfo (void ) { struct proc *p = uint64 addr; if (argaddr(0 , &addr) < 0 ) return -1 ; struct sysinfo info ; info.freemem = freekmem(); info.nproc = nproc(); if (copyout(p->pagetable, addr, (char *)&info, sizeof (info)) < 0 ) return -1 ; return 0 ; } uint64 freekmem (void ) { uint64 sum = 0 ; struct run *r ; acquire(&kmem.lock); r = kmem.freelist; while (r) { sum++; r = r->next; } release(&kmem.lock); return sum * PGSIZE; } uint64 nproc (void ) { uint64 n = 0 ; struct proc *p ; for (p = proc; p < &proc[NPROC]; p++){ if (p->state!= UNUSED) n++; } return n; }
lab3 pgtb vmprint 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void vmprintf (pagetable_t pagetable) { printf ("page table %p\n" , pagetable); for (int i = 0 ; i < 512 ; i++) { pte_t pte = pagetable[i]; if ((pte & PTE_V) && (pte &(PTE_R|PTE_W|PTE_X))==0 ) { printf ("..%d: pte %p pa %p\n" , i, pte, PTE2PA(pte)); pagetable_t next = (pagetable_t )PTE2PA(pte); for (int j = 0 ; j < 512 ; j++) { pte_t pte1 = next[j]; if ((pte1 & PTE_V) && (pte1 & (PTE_R|PTE_W|PTE_X))==0 ) { printf (".. ..%d: pte %p pa %p\n" , j, pte1, PTE2PA(pte1)); pagetable_t nnext = (pagetable_t )PTE2PA(pte1); for (int k = 0 ; k < 512 ; k++) { pte_t pte2 = nnext[k]; if ((pte2 & PTE_V)){ printf (".. .. ..%d: pte %p pa %p\n" , k, pte2, PTE2PA(pte2)); } } } } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 xv6 kernel is booting hart 2 starting hart 1 starting page table 0x0000000087f6e000 ..0: pte 0x0000000021fda801 pa 0x0000000087f6a000 .. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000 .. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000 .. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000 .. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000 ..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000 .. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000 .. .. ..510: pte 0x0000000021fdd807 pa 0x0000000087f76000 .. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000 init: starting sh
从图片3-4可以看到,这段地址是exec init的页表,exec为text和data段分配一个page也就是0,为stack分配一个page也就是2,而中间1是guarde page,程序在用户模式下访问会报错,最后510,511刚好符合trampoline和tramframe
A kernel page table per process 1、在struct proc加上内核页表字段pagetable_t kpagetable
2、为一个新进程生成内核页表,并设置映射关系和写入satp寄存器,因此这三个函数跟操作内核页表实现一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 pagetable_t prockptinit () { pagetable_t kptb = (pagetable_t ) kalloc(); memset (kptb, 0 , PGSIZE); prockptmap(kptb, UART0, UART0, PGSIZE, PTE_R | PTE_W); prockptmap(kptb, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W); prockptmap(kptb, CLINT, CLINT, 0x10000 , PTE_R | PTE_W); prockptmap(kptb, PLIC, PLIC, 0x400000 , PTE_R | PTE_W); prockptmap(kptb, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X); prockptmap(kptb, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W); prockptmap(kptb, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X); return kptb; } void prockptmap (pagetable_t kpt, uint64 va, uint64 pa, uint64 sz, int perm) { if (mappages(kpt, va, sz, pa, perm) != 0 ) panic("kvmmap" ); } void procinithart (pagetable_t kpt) { w_satp(MAKE_SATP(kpt)); sfence_vma(); } void freeprockpt (pagetable_t kpt) { for (int i = 0 ; i < 512 ; i++){ pte_t pte = kpt[i]; if ((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0 ){ uint64 child = PTE2PA(pte); freeprockpt((pagetable_t )child); kpt[i] = 0 ; } } kfree((void *)kpt); }
3、在allocproc每次进程创建时调用prockptinit生成内核页表,并将procinit函数功能迁移到allocproc中为分配内核栈和调用prockptmap设置映射关系
4、每当切换进程时同时切换进程内核页表,因此在scheduler函数调用procinithart切换和kvminithart切回
5、调用freeproc释放进程时释放内核页表,参考freewalk
记录错误:
在allocproc分配内核栈先p->context.sp = p->kstack + PGSIZE;然后再分配导致一直卡住
kvmpa内核栈虚拟地址转换物理地址没有修改成进程独自的内核页表
test sbrkfail: panic: prockptmap映射关系设置错误,释放进程时没有解除内核栈映射调用uvmunmap
Simplify copyin/copyinstr 一般情况在用户空间我们可以直接解引用srcva,而内核空间没有这个虚拟地址的映射,需要将其转换为物理地址
对比一下copy_in和copyin_new,需要将srcva转换为物理地址的page+偏移量,在这一个实验通过将用户页表映射复制到内核页表映射使得内核也可以直接访问srcva地址
1 2 3 va0 = PGROUNDDOWN(srcva); pa0 = walkaddr(pagetable, va0); memmove(dst, (void *)(pa0 + (srcva - va0)), n);
1 memmove((void *) dst, (void *)srcva, len);
copy函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void u2kcopy (pagetable_t uptb, pagetable_t kptb, uint64 va, uint64 sz) { pte_t *pte, *pte1; for (; va < sz; va += PGSIZE) { if ((pte = walk(uptb, va, 0 )) == 0 ) panic("u2kmap: walk" ); if ((pte1 = walk(kptb, va, 1 )) == 0 ) panic("u2kmap: walk" ); *pte1 = *pte & ~(PTE_U); } }
然后给fork,exec,growproc调用u2kcopy,因为这些改变了pagetable,不要忘记给userinit复制映射关系,不然一直卡在启动界面
记录错误:
缺页错误,gdb找到调用copyin_new的上一个函数调用是fork发现u2kcopy复制映射到p而不是np
(srcva >= p->sz || srcva+len >= p->sz || srcva+len < srcva)第三个测试是为了防止溢出,当len特别大就有可能发生
lab4 trap risc-v assembly
哪些寄存器保存函数的参数?例如,在main对printf的调用中,哪个寄存器保存13?
a0-a7寄存器,a2保存13
1 2 printf("%d %d\n", f(8)+1, 13); 24: 4635 li a2,13
main的汇编代码中对函数f的调用在哪里?对g的调用在哪里(提示:编译器可能会将函数内联)
看到g和f的汇编一模一样,因为f直接调用g,print中并没有看到调用f,而是编译器优化看,将函数内联直接得到12
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int g(int x) { 0: 1141 addi sp,sp,-16 2: e422 sd s0,8(sp) 4: 0800 addi s0,sp,16 return x+3; } 6: 250d addiw a0,a0,3 8: 6422 ld s0,8(sp) a: 0141 addi sp,sp,16 c: 8082 ret 000000000000000e <f>: int f(int x) { e: 1141 addi sp,sp,-16 10: e422 sd s0,8(sp) 12: 0800 addi s0,sp,16 return g(x); } 14: 250d addiw a0,a0,3 16: 6422 ld s0,8(sp) 18: 0141 addi sp,sp,16 1a: 8082 ret printf("%d %d\n", f(8)+1, 13); 24: 4635 li a2,13 26: 45b1 li a1,12
printf函数位于哪个地址?
34: 650080e7 jalr 1616(ra) # 680
unsigned int i = 0x00646c72;
…
0000000000000680 :
在main中printf的jalr之后的寄存器ra中有什么值?
jalr指令会跳转到ra+1616的地方,并且令ra为下一次指令地址,因此为38
执行以下代码显示的结果:576161==0xE110,i=0x00’64’6c’72,小端存储因此打印字符串就是'\0x72','\0x6c','\0x64','\0'
1 2 3 4 5 6 7 8 9 10 11 12 void main (void ) { printf ("%d %d\n" , f(8 )+1 , 13 ); unsigned int i = 0x00646c72 ; printf ("H%x Wo%s\n" , 57616 , &i); printf ("x=%d y=%d\n" , 3 ); exit (0 ); } $ call 12 13 HE110 World x=3 y=1
backtrace 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static inline uint64r_fp () { uint64 x; asm volatile ("mv %0, s0" : "=r" (x) ) ; return x; } void backtrace () { uint64 fp = r_fp(); printf ("backtrace:\n" ); while (PGROUNDUP(fp) == PGROUNDDOWN(fp) + PGSIZE) { printf ("%p\n" , *(uint64*)(fp-8 )); fp = *(uint64*)(fp-16 ); } }
alarm 添加系统调用,alarm需要进程记录触发时间间隔,计时器,处理函数,同时需要保存的寄存器,这里直接将整个trapfram保存起来了,在allocproc和freeproc初始化和释放新字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 uint64 sys_sigalarm (void ) { int interval; uint64 handler; if (argint(0 , &interval) < 0 ) return -1 ; if (argaddr(1 , &handler) < 0 ) return -1 ; myproc()->alarminterval = interval; myproc()->handler = (void (*)())handler; return 0 ; } uint64 sys_sigreturn (void ) { *myproc()->trapframe = *myproc()->oldtrapframe; myproc()->alarming = 0 ; return 0 ; }
在trap触发timer interrupt处修改切换的程序,sepc存放用户指令地址,stvec存放内核指令地址,这里需要切换epc为handler,同时为了通过test2,不应该在触发alarm的时候在handler中再次触发alarm,因此添加alarming字段表明正在发生alarm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 void usertrap (void ) { int which_dev = 0 ; if ((r_sstatus() & SSTATUS_SPP) != 0 ) panic("usertrap: not from user mode" ); w_stvec((uint64)kernelvec); struct proc *p = p->trapframe->epc = r_sepc(); if (r_scause() == 8 ){ if (p->killed) exit (-1 ); p->trapframe->epc += 4 ; intr_on(); syscall(); } else if ((which_dev = devintr()) != 0 ){ } else { printf ("usertrap(): unexpected scause %p pid=%d\n" , r_scause(), p->pid); printf (" sepc=%p stval=%p\n" , r_sepc(), r_stval()); p->killed = 1 ; } if (p->killed) exit (-1 ); if (which_dev == 2 && p->alarminterval > 0 && p->alarming == 0 ) { p->ticks++; if (p->ticks >= p->alarminterval) { p->alarming = 1 ; *p->oldtrapframe = *p->trapframe; p->trapframe->epc = (uint64)(p->handler); p->ticks = 0 ; } } if (which_dev == 2 ) { yield(); } usertrapret(); }
lab5:lazy page allocation stval包含无法被转换的地址,即缺页的那个地址
修改sbrk系统调用,当需要扩容时进行写时复制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 uint64 sys_sbrk (void ) { int addr; int n; if (argint(0 , &n) < 0 ) return -1 ; addr = myproc()->sz; if (n > 0 ) { myproc()->sz += n; } else if (n + addr > 0 ) { if (growproc(n) < 0 ) return -1 ; } else return -1 ; return addr; }
修改usertrap当触发13或15页面错误则分配一个page,并且通过vmprintf看到分配了两个页
.. .. ..4: pte 0x0000000021fd64df pa 0x0000000087f59000
1 2 3 4 5 6 7 8 9 10 11 } else if (r_scause() == 15 || r_scause() == 13 ) { uint64 va = r_stval(); if (va < PGROUNDDOWN(p->trapframe->sp) || va >= myproc()->sz || uvmalloc(p->pagetable, PGROUNDDOWN(va), va+1 ) == 0 ){ p->killed = 1 ; } } else { printf ("usertrap(): unexpected scause %p pid=%d\n" , r_scause(), p->pid); printf (" sepc=%p stval=%p\n" , r_sepc(), r_stval()); p->killed = 1 ; }
修改出现(pte = walk(pagetable, a, 0)) == 0和(*pte & PTE_V) == 0条件为true直接continue,不然报错
处理进程从sbrk()向系统调用(如read或write)传递有效地址,但尚未分配该地址的内存。
1 2 3 4 5 6 7 8 9 10 11 int argaddr (int n, uint64 *ip) { *ip = argraw(n); struct proc *p = uint64 va = *ip; if (walkaddr(p->pagetable, *ip) == 0 ) if (va < PGROUNDDOWN(p->trapframe->sp) || va >= myproc()->sz || uvmalloc(p->pagetable, PGROUNDDOWN(va), va+1 ) == 0 ) return -1 ; return 0 ; }
lab6: cow fork 添加RSW标志位标志cow映射
1 2 #define PTE_RSW (1L << 8)
因为父子进程共享页面,添加引用次数(同kmem添加自旋锁),因此在kinit初始化锁 initlock(&ref.lock, "ref");
1 2 3 4 5 struct ref_struct { struct spinlock lock; int refcnt[PHYSTOP/PGSIZE]; } ref;
修改kfree判断引用次数为0才真正删除,修改kalloc设置页引用次数为1
1 2 3 4 if (--ref.refcnt[(uint64)pa/PGSIZE] < 1 ) {release (&ref.lock);} else release (&ref.lock);
1 2 3 4 5 6 if (r) {memset ((char *)r, 5 , PGSIZE); acquire (&ref.lock);ref.refcnt[(uint64)r/PGSIZE] = 1 ; release (&ref.lock);}
因为struct ref_struct在kalloc.c中,添加以下四个函数读取cnt,addcnt,判断是否PTE_RSW,写时分配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void addrefcnt (uint64 pa) acquire (&ref.lock); ++ref.refcnt[pa/PGSIZE]; release (&ref.lock); } int refcnt (uint64 pa) return ref.refcnt[pa/PGSIZE]; } int cowpage (pagetable_t pagetable, uint64 va) pte_t *pte; if (va >= MAXVA || (pte = walk (pagetable, va, 0 )) == 0 || (*pte & PTE_RSW) == 0 ) return -1 ; return 0 ; } void * cowalloc (pagetable_t pagetable, uint64 va) pte_t *pte = walk (pagetable, va, 0 ); uint64 pa = PTE2PA (*pte); if (ref.refcnt[pa / PGSIZE] < 2 ) { *pte = (*pte | PTE_W) & ~PTE_RSW; return (void *)pa; } else { char * mem = kalloc (); if (mem == 0 ) return 0 ; memmove (mem, (char *)pa, PGSIZE); int flags = (PTE_FLAGS (*pte) & ~PTE_RSW) | PTE_W ; *pte = PA2PTE ((uint64)mem) | flags; kfree ((void *)pa); return (void *)mem; } }
修改uvmalloc(删除kalloc,修改映射关系到pa并且添加PTE_RSW标志)
1 2 3 4 if (flags & PTE_W) { flags = (flags & ~PTE_W) | PTE_RSW; *pte = PA2PTE (pa) | flags; }
修改usertrap当发生pagefault时写时复制
1 2 3 4 5 6 7 } else if (r_scause () == 13 || r_scause () == 15 ) { uint64 va = r_stval (); if (va >= p->sz || cowpage (p->pagetable, va) != 0 || cowalloc (p->pagetable, va) == 0 ) p->killed = -1 ; }
修改copyout在遇到COW页面时使用同页面错误相同方案
1 2 3 if (cowpage (pagetable, va0) == 0 ) { pa0 = (uint64)cowalloc (pagetable, va0); }
记录错误:
发生scause=5,sepc=0x386错误,跟正确的对比才发现当PTE_W时设置flags出错,直接*pte &= flags;错误地把除10位flags之外的位置零了
lab7 multithreading switching between threads 同进程swtch一样添加上下文切换,ra和sp,添加context字段,汇编代码同swtch一样
1 2 t->context.ra = (uint64)func; t->context.sp = (uint64)t->stack+STACK_SIZE;
using threads 使用pthread_mutex_t确保多线程哈希表使用安全,为每个哈希桶分配lock,减少因为锁的性能下降
1 pthread_mutex_t lock[NBUCKET];
barrier 1 2 3 4 5 6 7 8 9 pthread_mutex_lock (&bstate.barrier_mutex);if (++bstate.nthread == nthread) { ++bstate.round; bstate.nthread = 0 ; pthread_cond_broadcast (&bstate.barrier_cond); } else { pthread_cond_wait (&bstate.barrier_cond, &bstate.barrier_mutex); } pthread_mutex_unlock (&bstate.barrier_mutex);
lab8 locks Memory allocator 为每个cpu分配struct kmem,并且在kalloc空闲链表不足时窃取其他cpu的空闲链表的一部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void *kalloc (void ) struct run *r; push_off (); int id = cpuid (); acquire (&kmem[id].lock); r = kmem[id].freelist; if (r) kmem[id].freelist = r->next; release (&kmem[id].lock); if (!r) { for (int i = 0 ; i < NCPU; ++i) { if (i == id) continue ; acquire (&kmem[i].lock); r = kmem[i].freelist; if (r) kmem[i].freelist = r->next; release (&kmem[i].lock); if (r) break ; } } pop_off (); if (r) memset ((char *)r, 5 , PGSIZE); return (void *)r; }
1 2 3 4 5 6 7 8 9 10 11 void kfree (void *pa) ... push_off (); int id = cpuid (); acquire (&kmem[id].lock); r->next = kmem[id].freelist; kmem[id].freelist = r; release (&kmem[id].lock); pop_off (); }
Buffer cache 将bcache的单个缓存区链表替换为哈希表,用timestamp替换lru置换
添加哈希桶,根据trap.c的ticks实现timestamp并为struct buf添加ticks字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #define NBUCKET 13 const uint UINT_MAX = -1 ;struct spinlock tick_lock;uint ttt; struct hashbuf { struct spinlock lock; struct buf head; }; struct { struct spinlock lock; struct buf buf[NBUF]; struct hashbuf buckets[NBUCKET]; } bcache;
在binit初始化每个哈希桶的head
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void binit (void ) struct buf *b; initlock (&tick_lock, "time" ); initlock (&bcache.lock, "bcache" ); for (int i = 0 ; i < NBUCKET; ++i) { char name[10 ]; snprintf (name, sizeof (name), "bcache_%d" , i); initlock (&bcache.buckets[i].lock, name); bcache.buckets[i].head.prev = &bcache.buckets[i].head; bcache.buckets[i].head.next = &bcache.buckets[i].head; } for (b = bcache.buf; b < bcache.buf+NBUF; b++){ int hash = (b - bcache.buf) % NBUCKET; struct hashbuf *hb = &bcache.buckets[hash]; b->next = hb->head.next; b->prev = &hb->head; initsleeplock (&b->lock, "buffer" ); hb->head.next->prev = b; hb->head.next = b; } }
添加tick函数进行计时,在bget函数中倘若当前哈希桶的buffer cache未命中,把no cached的情况单独拎出来写在nocached函数中同时进行串行化回收,这样brelse函数只需要修改时间戳同时避免锁争用,最终缓存区的回收只在nocached进行,需要一个全局锁用bcache.lock代替,注意将缓存区从一个哈希桶移动到另一个哈希桶的锁使用和释放时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 int tick () int ret; acquire (&tick_lock); ret = ++ttt; release (&tick_lock); return ret; } static struct buf * nocached (uint dev, uint blockno){ struct buf *b, *lru = 0 ; uint min = UINT_MAX; int hash = -1 ; acquire (&bcache.lock); for (int i = 0 ; i < NBUCKET; ++i) { acquire (&bcache.buckets[i].lock); for (b = bcache.buckets[i].head.prev; b != &bcache.buckets[i].head; b = b->prev){ if (b->refcnt == 0 && b->ticks < min) { min = b->ticks; lru = b; hash = i; } } release (&bcache.buckets[i].lock); } if (lru && hash != -1 ) { acquire (&bcache.buckets[hash].lock); lru->next->prev = lru->prev; lru->prev->next = lru->next; release (&bcache.buckets[hash].lock); hash = (dev+blockno) % NBUCKET; acquire (&bcache.buckets[hash].lock); lru->next = bcache.buckets[hash].head.next; lru->prev = &bcache.buckets[hash].head; bcache.buckets[hash].head.next->prev = lru; bcache.buckets[hash].head.next = lru; lru->dev = dev; lru->blockno = blockno; lru->valid = 0 ; lru->refcnt = 1 ; lru->ticks = tick (); release (&bcache.buckets[hash].lock); release (&bcache.lock); acquiresleep (&lru->lock); return lru; } panic ("bget: no buffers" ); } static struct buf *bget (uint dev, uint blockno){ struct buf *b; int hash = (dev+blockno) % NBUCKET; acquire (&bcache.buckets[hash].lock); for (b = bcache.buckets[hash].head.next; b != &bcache.buckets[hash].head; b = b->next){ if (b->dev == dev && b->blockno == blockno){ b->refcnt++; b->ticks = tick (); release (&bcache.buckets[hash].lock); acquiresleep (&b->lock); return b; } } release (&bcache.buckets[hash].lock); return nocached (dev, blockno); } void brelse (struct buf *b) if (!holdingsleep (&b->lock)) panic ("brelse" ); releasesleep (&b->lock); int hash = (b->dev+b->blockno) % NBUCKET; acquire (&bcache.buckets[hash].lock); b->refcnt--; b->ticks = tick (); release (&bcache.buckets[hash].lock); }
lab9 file system Large files 为inode一个二级间接块,添加和修改宏
1 2 3 4 #define NDIRECT 11 #define NINDIRECT (BSIZE / sizeof(uint)) #define N2INDIRECT (NINDIRECT * NINDIRECT) #define MAXFILE (NDIRECT + NINDIRECT + N2INDIRECT)
修改bmap增加一下代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 bn -= NINDIRECT; if (bn < N2INDIRECT){ uint l2_idx = bn / NINDIRECT; uint l1_idx = bn % NINDIRECT; if ((addr = ip->addrs[NDIRECT+1 ]) == 0 ) ip->addrs[NDIRECT+1 ] = addr = balloc(ip->dev); bp = bread(ip->dev, addr); a = (uint*)bp->data; if ((addr = a[l2_idx]) == 0 ){ a[l2_idx] = addr = balloc(ip->dev); log_write(bp); } brelse(bp); bp = bread(ip->dev, addr); a = (uint*)bp->data; if ((addr = a[l1_idx]) == 0 ) { a[l1_idx] = addr = balloc(ip->dev); log_write(bp); } brelse(bp); return addr; }
修改itrunc增加以下代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct buf * bp1 ;uint *a1; if (ip->addrs[NDIRECT+1 ]){ bp = bread(ip->dev, ip->addrs[NDIRECT+1 ]); a = (uint*)bp->data; for (j = 0 ; j < NINDIRECT; j++){ if (a[j]) { bp1 = bread(ip->dev, a[j]); a1 = (uint*)bp1->data; for (i = 0 ; i < NINDIRECT; i++) if (a1[i]) bfree(ip->dev, a1[i]); brelse(bp1); bfree(ip->dev, a[j]); } } brelse(bp); bfree(ip->dev, ip->addrs[NDIRECT+1 ]); ip->addrs[NDIRECT+1 ] = 0 ; }
Symbolic links 添加软连接系统调用,修改sys_open进行符号链接跟随,最大深度为10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 uint64 sys_open (void ) { ... begin_op(); if (ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){ iunlockput(ip); end_op(); return -1 ; } if (ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)) { for (int i = 0 ; i < MAX_SYMLINK_DEPTH; ++i) { if (readi(ip, 0 , (uint64)path, 0 , MAXPATH) != MAXPATH) { iunlockput(ip); end_op(); return -1 ; } iunlockput(ip); if ((ip = namei(path)) == 0 ) { end_op(); return -1 ; } ilock(ip); if (ip->type != T_SYMLINK) break ; } if (ip->type == T_SYMLINK) { iunlockput(ip); end_op(); return -1 ; } } ... } uint64 sys_symlink (void ) { char target[MAXPATH], path[MAXPATH]; struct inode *ip ; if (argstr(0 , target, MAXPATH) < 0 || argstr(1 , path, MAXPATH) < 0 ) return -1 ; begin_op(); if ((ip = create(path, T_SYMLINK, 0 , 0 )) == 0 ){ end_op(); return -1 ; } if (writei(ip, 0 , (uint64)target, 0 , MAXPATH) != MAXPATH) { iunlockput(ip); end_op(); return -1 ; } iunlockput(ip); end_op(); return 0 ; }
我在参考sys_link后调用sys_symlink系统调用的时候发生了死锁,发现在create函数中已经对创建的inode进行加锁,因此调用create后无需再加锁
lab10:mmap lab11:Network driver